背景 / Background
今年上半年的时候,公司内部组织过一次全球性Hackathon大赛,我被被任命为公司亚太区的SPOC,负责亚太区技术团队Hackathon大赛的推广及本地组织者。余热未了,最近亚太区技术Boss邮件问我可不可以做一个提供自助服务的ChatBots原型。正好几年前研究过相关的东西(NLP\ML\DL),虽说没有深入到理论层面,但是结合当下业务的某些场景,倒是可以快速的做些应用原型玩玩。
对于本文,主要涉及到功能探索和构建方面的内容,并不会就“为什么做这个功能”的问题本身展开描述。不会过多站在产品角度来写,更多的是记录应用具体的技术方案来实现的过程。另外对于NLP/ML/DP也不会深入到理论层面,因为这不是一篇文章就可以写清楚的,或者说我能写的很清楚。
探索 / Explore
原型的功能定义很简单,需要具备以下两个基本功能:
1. 简单陪聊,可人工训练
2. 自助个性化定制服务,根据用户的输入(Audio/Text)提供个性化服务
一是简单陪聊,所谓陪聊就是在用户知道是跟机器人聊天的情况下,但又能聊的很愉悦。为什么这么说呢?目前市面上有部分已知的聊天机器人在面对简单的会话的时候,尚且能应付人类。一旦深入聊天,涉及到复杂的上下文会话,机器人的愚(Zhi)蠢(Shang)就暴露无疑了。这时候用户可能没有继续与该机器人聊下去的欲望和耐心。当然,这不代表我打算做一个能深度陪聊的机器人,毕竟以现有的资源要做到还很困难。这也是我为什么要定义为简单陪聊。虽说定义简单,还是会用到机器学习和自然语言处理相关的技术方案,而不是纯粹的简单指令匹配,通过ML/NLP或多多少能改善一些用户体验。让这个陪聊功能在一定程度上需要具备“以其人之道还治其人之身”的能力,即学习能力。自打Machine Learning提出之后,这些年聊天机器人原型不少。像斯坦福和国内清华大学的学生团队都有相继推出类似的原型,商业领域的谷歌、苹果、微软等巨头也有推出类似服务。
提到机器人聊天,我想延伸再聊聊人工智能。正如图灵测试对人工智能的定义是“你不知道对面是人还是机器的时候,你觉得他是人类”。在我看来,基于经典的冯若依曼架构很难做到这一点。当然,如果把这个架构模型抽象出来,以后不管怎么进化,始终是大同小异。我对于现有的人工智能的理解是本质上基于大规模训练得到产生行为的数据,通过算法来匹配和构建方案给予人类反馈。
包括去年很出彩的AphlaGo,它本质上不具备真正的思维能力,只是通过人类的训练(机器自我对弈)生产行为数据和算法匹配来应对人类。话说回来,人类的大脑也是在不断的学习过程中,沉淀知识数据和构建一些应对外界的刺激给予反射行为,本质上抽象出来一样是处理事务的一套算法。俗话说做人要有一套以自己的为人处世的方式方法,抽象出来理解就是计算机算法。
二是自助服务,所谓自助就是用机器人来增强业务上的某些场景服务体验,以达到好用户体验。举个栗子,假设你这时候不知道自己怎么学习英语,那么此时你可能需要一个学习顾问来给予帮助,并且顾问需要站在你的角度给一些学习方面的建设性的意见和方案。在这个过程中,顾问需要知道你是否对某些领域感兴趣、当前的英语水平、家庭住址等等。通过这些信息,顾问就帮你分析匹配最优资源和内容,以达到给予个性化学习方案。
顾问可以是一个人,也可以是一个机器人。TA们要做的事情是相同的,但机器比人更高效,特别适用在Online方面。前面也谈到了机器人聊天对于会话上下文的理解和处理,本质上这个聊天的能力会是自助服务的前置能力。首先要对用户的输入进行转换(例如,语音识别转文本),然后进行处理。也就是NLP的过程,理解用户上下文。当然,前置条件是我们已经对自己的学习资源和内容进行了索引,以及有课程方案的策略池。这样才能在经过NLP处理之后,匹配上资源和内容最终给用户产生个性化方案。
构建 / Build
虽然只是一个原型,我也会尽量在构建过程,以项目工程的形式来处理确保完整性。以下是在构建过程中用到的技术栈:
服务器: CENTOS 7.2 / Ubuntu(Docker Image)
应用容器引擎: Docker
研究方向:Nature Language Process / Machine Learning
HTTP服务器: Nginx / uwsgi
数据传输协议: JSON via HTTP
应用架构: RESTful
后端语言: Python
Python API框架: Flask / Flask_restful
前端语言: Javascript / html / css
RIA框架: Angular.js
前端开发工具: Pug / less / gulp
持久化:Mongodb
从Client/Presentation层面来说,原型提供的服务抽象出来也就是一个会话框,对用户而言功能很简单。考虑到基于Web技术栈,所以UI这块采用技术人员常用的前端神器Bootstrap布局构建,色调搭配随便参考了一个网上的。界面没有花太多精力,所以看起来比较粗糙,毕竟原型的侧重点不是在UI交互。最后原型客户端界面长成下面这样
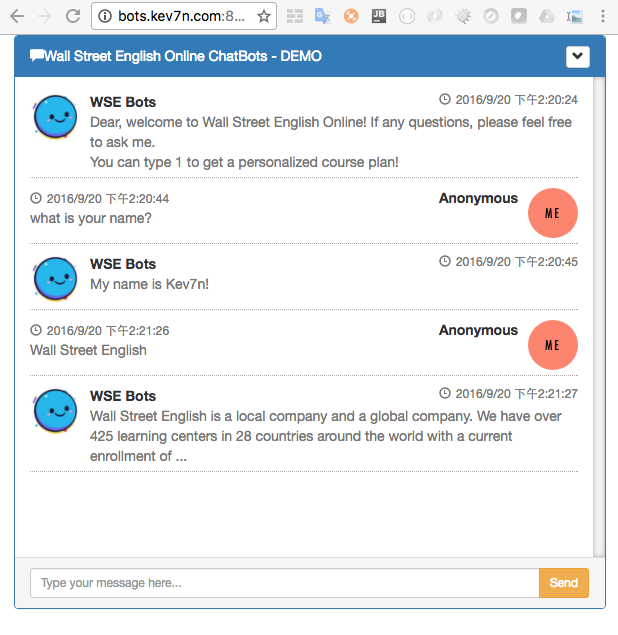
前端框架到用到了谷歌开源的Angular.js、css用Less生成,html采用Pug生成,构建任务采用Gulp,这些基本上是前端开发的常见组合。后端开发语言用的是Python,它对于数据处理是天生友好,最关键在于有各种齐全的数学库,所以有很多数学科学家喜欢用它,有不少数据挖掘、网络爬虫等框架就基于它研发。平时比较喜欢用Flask框架,它足够轻量,开发语言就决定用Py了。对于采用Docker部署,这个就不用解释太多了吧,就一个字“好”。技术栈中规中矩,没有奇形怪状的框架或者采用特别小众的开发语言。数据的持久化这块,考虑到没有复杂的业务逻辑和业务关系,所以采用NOSQL数据库Mongodb。
本原型需要构建的重点在于后端提供的服务,复杂度主要是自然语言处理和学习内容映射这块。需要理解用户的输入然后内容匹配分析,然后构建方案响应给用户。对于理解用户的输入,本质上就是顾问对用户提问之后所收集的信息的进行分析。这个分析会包含标识化、句子切分、部分词性标注、名称抽取、组块、解析等过程,根据这些任务产生关键信息,最终用于学习内容的索引信息匹配。对关键信息的解析匹配之后,根据预置的方案策略池予以组合产生个性化学习方案提供给学生。考虑到原型的快速构建,基于现有NLP框架/服务来应用构建是最好的方案。对于NLP这块,成熟的方案/算法模型比较多,像斯坦福大学的CoreNLP就是个不错选择,支持大多数常用的任务,所以就选定了它来构建NLP服务器。
部署 / Deployment
未完待续...
结束语 / The End
所有源代码均开源(已完成60%)在 https://github.com/Hell0wor1d/chatbots